1. Pandas란?
- panel data의 줄임말로 파이썬의 구조화된 데이터 처리를 지원하는 Python의 라이브러리이다.
- 파이썬에서 일종의 엑셀과 같은 역할을 하여 데이터를 전처리하거나 통계 처리시 많이 활용하는 피벗(pivot) 테이블 등의 기능을 사용할 때 쓰는 것이다
특징
- 고성능array 계산라이브러리인 numpy와통합하여, 강력한“스프레드시트” 처리기능을제공
- 인덱싱, 연산용함수, 전처리함수등을제공함
- 데이터처리 및 통계분석을위해 사용
2. Series
2.1 Series : DataFrame 중 하나의 Column에 해당하는 데이터의 모음 Object
- 인덱스와 데이터로 구성되어 있다. 인덱싱을 할 때, 기본값이 숫자이고, 문자로도 지정할 수 있다.
- numpy.ndarray의 서브 클래스
- Data는 어느 타입이든 가능하다
- Duplicate가 가능하다
2.2 사용법
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
list_data=[6,7,8,9,10]
example_obj = Series(data=list_data)
example_obj
'''
0 6
1 7
2 8
3 9
4 10
dtype: int64
'''
dict_data={"a":1,"b":2,"c":3,"d":4,"e":5}
example_obj = Series(dict_data, dtype=np.float32,name="example_data")
example_obj
'''
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
'''- (객체).index
dict_data={"a":1,"b":2,"c":3,"d":4,"e":5}
example_obj = Series(dict_data, dtype=np.float32,name="example_data")
example_obj
'''
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
'''
example_obj.index # Index(['a', 'b', 'c', 'd', 'e'], dtype='object')- data index에 접근하기
example_obj["a"] # 1.0- data index에 값 할당하기
example_obj["a"]=3.2
example_obj
'''
a 3.2
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
'''- astype : 데이터의 자료형을 바꿔준다.
example_obj=example_obj.astype(float)
# float타입으로 변경- values : 값(data) 리스트를 뽑아낸다.
example_obj.values # array([3.2, 2. , 3. , 4. , 5. ], dtype=float32)다음과 같이 index값을 기준으로 Series를 생성 할 수 있다.
dict_data_list={"a":1,"b":2,"c":3,"d":4,"e":5}
indexes = ["a","b","c","d","e","f","g","h"]
series_obj_list=Series(dict_data_list, index=indexes)
series_obj_list
'''
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
f NaN
g NaN
h NaN
dtype: float64
'''위에서 NaN값이 출력되는 이는 인덱스 기준으로 Series를 생성하기 때문이다.
3. Dataframe : Data Table 전체를 포함하는 Object
- numpy를 사용
- 각 컬럼은 다른 타입을 사용할 수 있다.
- 인덱스가 Row 뿐만아니라 Column에도 있다.
- Size mutable
from pandas import Series,DataFrame
import pandan as pd
import numpy as np
DataFrame()data = {'name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'year': [2012, 2012, 2013, 2014, 2014],
'reports': [4, 24, 31, 2, 3]}
df = pd.DataFrame(data, index = ['Cochice', 'Pima', 'Santa Cruz', 'Maricopa', 'Yuma'])
df
- dataframe 생성
DataFrame(data,columns=["name","year"])
DataFrame(data,columns=["name","year","reports","city"])

- dataframe indexing
loc은 index 이름, iloc은 index number이다.
df.loc["Pima"]
'''
name Molly
year 2012
reports 24
Name: Pima, dtype: object
'''
df["name"].iloc[1:] # df의 "name"의 1번째 인덱스부터 나타낸다.
'''
Pima Molly
Santa Cruz Tina
Maricopa Jake
Yuma Amy
Name: name, dtype: object
'''
- df.T : transpose, 즉 행과 열을 서로 바꾼다.(전치행렬)
- df.values : 데이터 값만 변환
- df.to_csv() : csv로 변환
- del df[(삭제할 컬럼)] : 실제 메모리에 할당된 주솟값까지 완전 삭제
- df.drop((컬럼),axis=1) : 해당 컬럼을 누락시킴(dataframe 자체는 변화가 없다.)
3.1 Selection & drop
- df["컬럼명"] 또는 df["column1","column2"] : 해당 컬럼(들)의 데이터를 나타낸다.
import numpy as np
import pandas as pd
df=pd.read_excel("엑셀파일 경로(상대경로 or 절대경로)") # 엑셀파일을 읽는다.
df.head()
df.head(2) # 가장 위로부터 두줄
df.head(2).T
- df[[["column"]]은 df["column"]과는 다르게 DataFrame 형식으로 나온다.
ex)


- df[:(숫자)] : column 이름 없이 사용하는 index number는 row 기준 표시
- df["컬럼명"][:3] : column 이름과 함께 row index 사용시, 해당 column 만 표시

- index 변경
df.index = df["account"]
del df["account"]
df.head()- basic, loc, iloc selection
df[["name","street"]][:2] # column과 index number
df.loc[[211829,320563],["name","street"]] # Column과 index name
df.iloc[:10,:3] # column number와 index number- reindex
df.reset_index() # 인덱스가 새로 생성된 값을 보여준다. 단, df자체는 변하지 않음
df.reset_index(drop=True) # 기존 인덱스 삭제
df.reset_index(inplace=True, drop=True) # inplace는 df자체가 변함- drop
df.drop(인덱스) # 해당 인덱스의 row를 삭제
df.drop((list형)) # 해당 인덱스들의 row를 삭제
df.drop([drop할 컬럼값],axis=1) # 해당 컬럼을 drop하나 df는 변하지 않음
# df를 변화시키기 위해서 inplace=True를 추가
df.drop([drop할 컬럼값],axis=1,inplace=True)3.2 dataframe operations
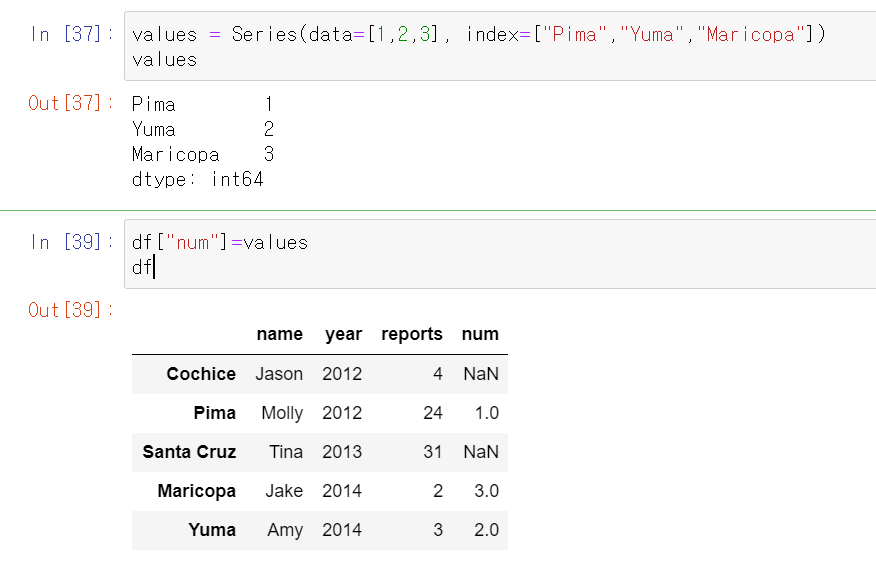
- series operation : index 기준으로 연산수행, 겹치는 index가 없다면 NaN으로 반환
TMI
pandas 에서 엑셀 파일을 부르는 모듈 : xlrd
conda install --u xlrd
'BoostCamp AI Tech - U Stage' 카테고리의 다른 글
| BoostCamp AI Tech - Day10 (0) | 2021.02.01 |
|---|---|
| BoostCamp AI Tech - Day09 (0) | 2021.01.28 |
| BoostCamp AI Tech - Day07 (0) | 2021.01.26 |
| BoostCamp AI Tech - Day06 (0) | 2021.01.25 |
| BoostCamp AI Tech - Day05 (0) | 2021.01.22 |

댓글