Optimization
1. 알아두어야할 용어
- Gradient Descent : local minimum of a differentiable function을 찾기위해 1차미분한 값을 반복적으로 최적화 시키는 것
1.1 최적화(Optimization)에서 알아야할 용어
- Generalization : 학습 데이터와 테스트 데이터가 얼마나 차이나는 지 보여주는 지표
Generalization이 좋다 -> 이 네트워크 성능이 학습데이터와 비슷하게 나올 것이라는 보장을 해준다

- Under-fitting vs. Over-fitting
-> Over-fitting : 일반적으로 학습데이터가 잘 동작하지만, 테스트 데이터가 제대로 동작하지 않는 현상
-> Under-fitting : 네트워크가 간단하거나 학습횟수가 적어 학습데이터가 동작하지 않는 현상
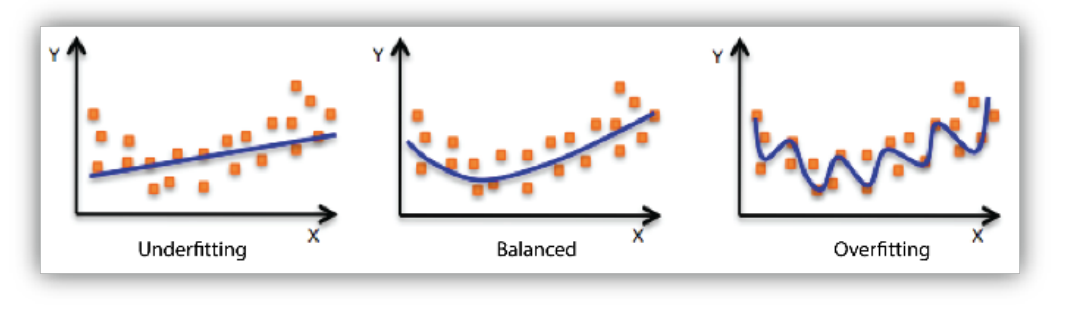
- Cross validation

학습에서는 학습 데이터(Traning data)와 Validation data를 활용해야하고 Test Data는 어떤 방법으로도 활용해선 안된다.
- Bias and Variance
(그림 참고)
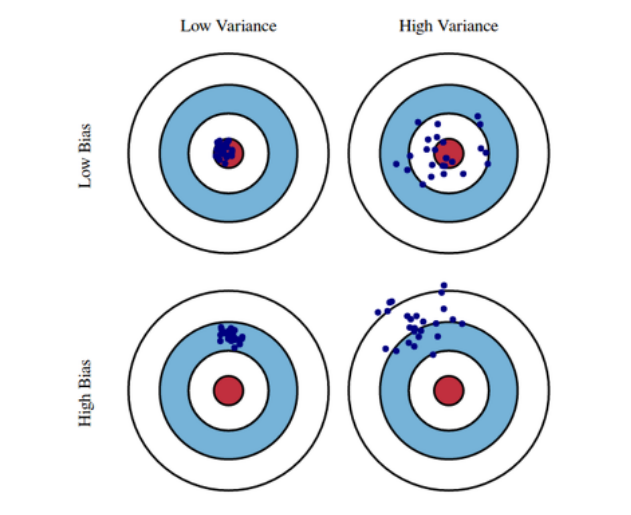
- Bias and Variance Tradeoff

bias와 variance를 동시에 줄이는 모델을 얻기 힘들다는 의미이다.
- Bootstrapping

어떤 고정된 데이터가 있을 때, 무작위로 추출하여 metric을 만들거나 테스팅을 하는 것
- Bagging(Bootsrapping aggregating)
-> Bootstrapping으로 학습한 다수의 모델들을 통해 Output을 평균을 내는 것
- Boosting
-> 분류하기 어려운 학습 데이터를 대상에 초점을 둔다.
-> 이러한 학습데이터를 weak learners라고 하고 이것들을 조합하여 모델을 sequencial하게 합쳐 하나의 강한 모델을 만드는 것

2. Practical Gradient Descent Methods
- Stochastic gradient descent(SGD)
-> 하나의 샘플을 통해 gradient를 업데이트 하는 것
- Mini-batch gradient descent
-> 데이터의 일부를 통해 계산해낸 gradient를 업데이트를 하는 것
- Batch gradient descent
-> 데이터를 일괄적으로 계산해낸 gradient를 업데이트를 하는 것
※ Batch-size Matters : Batch size가 너무 적으면 학습이 안되고, 너무 많은 뉴럴 네트워크 동작이 제대로 이뤄지지 않을 수도 있다.


2.1 Gradient Descent Methods
- Stochastic gradient descent
-> $W_{t+1}\leftarrow W_t-\eta g_t$
($\eta $$ : Learning rate, $$g_t $ : Gradient)
-> 문제점 : Step Size를 잡는 것이 어렵다. 즉, Learning rate를 적절하게 잡는 것이 중요하다.
- Momentum
-> $a_{t+1}\leftarrow \beta a_t+gt$
-> $W_{t+1}<-W_{t+1}\leftarrow W_t-\eta a_{t+1}$
($\beta$ : momentum(hyper parameter), $a_{t+1}$ : accumulation)
- Nesterov accelerated gradient
-> $a_{t+1}\leftarrow \beta_{a_t}+\triangledown L(W_t-\eta \beta a_t)$
-> $W_{t+1}<-W_{t+1}\leftarrow W_t-\eta a_{t+1}$
($\triangledown L(W_t-\eta \beta a_t)$ : Lookahead gradient)

- Adagrad
-> $W_{t+1}=W_t-\frac{\eta}{\sqrt{G_t+\epsilon}}g_t$
($G_t$ : 지금까지 Gradient가 얼마나 변했는 지의 값을 제곱해서 더한 것(Sum of gradient squares))
($\epsilon$ : numerical stability, 0으로 나눔을 방지하는 값)
- Adadelta
앞선 Adagrad가 가진 $G_t$가 monotonically하게 커지는 것을 막는다.

- RMSprop
-> Geoff Hinton의 딥러닝 강의 도중 제안된 adaptive learning rate, 출판되지 안흥ㅁ

- Adam(Adaptive Moment Estimation)


3. Regularization
- 학습데이터뿐만 아니라 테스트 테이터에 Generalization을 위해 학습을 방해할 수 있도록 하는 것
3.1 Early Stopping

지금까지 했던 모델 성능 또는 Loss를 보고 그 Loss가 커지기 시작할 가능성이 큰 곳에서 Stopping을 하는 것, 이를 위해 추가적인 validation data가 필요하다.
3.2 Parameter Norm Penalty
- Neural Network 파라미터가 너무 커지지 않게 막는 것, 즉 W가 작으면 작을수록 좋다.
$total cost = loss(D;W)+\frac{\alpha}{2}\left \| W \right \|_{2}^{2}$
($\frac{\alpha}{2}$ $\left \| W \right \|_{2}^{2}$ : Parameter Norm Penalty)
3.3 Data Augmentation
- 주어진 데이터를 일정 한도 내에서 일부 변환 등으로 늘리는 것


3.4 Noise Robustness
- 입력값 또는 Weight에 noise를 넣는 것이다.

3.5 Label Smoothing
- Train 단계에서 학습데이터 2개를 뽑아서 그 두개를 섞어준다.

- Cut-Out : 이미지 하나가 주어졌을 때, 일정 영역을 빼버리는 것
- Cut-Mix : 자연스럽게 blending이 아닌, 일정 영역을 A, 일정 영역을 B 이런 식으로 섞는 것이다.

Cut-Mix를 사용하는 것을 권장, 들이는 노력대비 성능이 좋다고 한다.
3.6 Dropout
Nueral network의 Weight를 임의로 0으로 바꾼다. 각각의 뉴런들이 Robust하다고 해석을 한다고 한다.

3.7 Batch Normalization
- BN(Batch Normalization)을 적용하는 레이어에 statistics를 정규화하는 것. Internal Convariate Shift를 줄인다. 그러면서 네트워크 학습이 된다고 한다. BN을 활용하면 layer를 쌓아 나가면 성능이 좋아진다고 한다. 특히, 간단한 분류문제를 풀 때 성능이 좋다고 한다.


4. CNN 첫 걸음
4.1 Convolution 연산
커널(kernel)을 입력벡터 상에서 움직여 가면서 선형모델과 합성함수가 적용되는 구조이다. (V : 커널, k는 커널의 사이즈)

위의 그림에서 입력벡터 x를 모두 활용하는 것이 아니라 커널 사이즈 k에 대응되는 만큼 입력벡터에서 추출한다.

중요한 것은 기존 다층 신경망(MLP)의 가중치 행렬과 다르게 이곳에 적용하는 커널은 고정되어 있다. 따라서, 고정된 커널을 적용할 수 있기 때문에, 파라미터의 개수를 줄이는 데 용이하다
4.2 Convolution 연산의 수학적인 의미
신호(signal)를 커널을 이용해 국소적으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것이다.

(continuous : 연속적인 공간, discrete : 이산 공간, 단 적용되는 방식은 동일하다)

전체공간에서는 cross-correlation과 convolution은 같이 성립하기 때문에 관용적으로 통틀어서 convolution 연산이라고 불렸던 것이다. 다만, 컴퓨터에서 사용할 때는 +,-를 사용할 때 차이가 있다.

커널은 정의역 내에서 움직여도 변하지 않고(translation invariant) 주어진 (파란색) 신호에 국소적(local)으로 적용한다. 노란색은 파란색 신호가 들어올 때 국소적으로 적용되는 연산이다. 따라서, 위의 사진처럼 검은색 결과가 나온다. 자세히보면, 파란색의 원래 signal 함수를 검은색으로 변환시켜 정보를 확산시키거나 추출, 감소 등을 한다. 이것이 'Convolution 연산'은 한다고 한다.
(예 : 영상처리에서 커널값에 따라, blur, top sobel 다양한 영상효과를 줄 수 있다.)
- Convolution 연산은 1차원뿐만 아니라 다양한 차원에서 계산 가능하다. 데이터의 성격에 따라 사용하는 커널이 달라진다.

4.3 Convolution 연산
2D-Conv 연산은 커널을 입력행렬 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조이다.
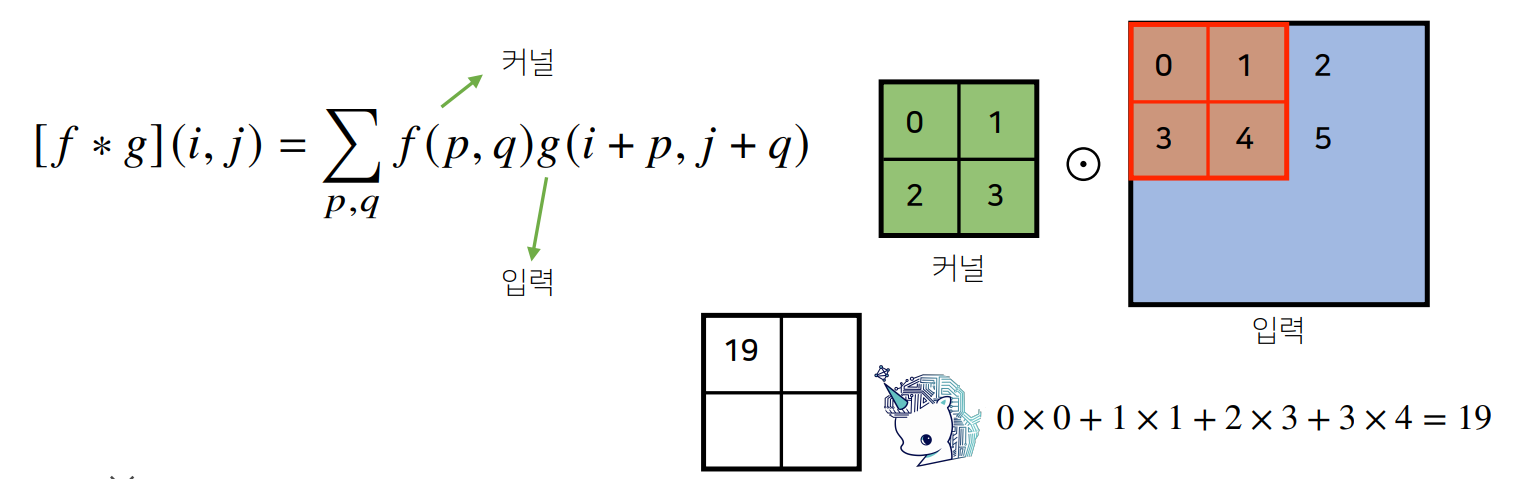

- 입력 크기를 ($H$,$W$), 커널 크기를 ($K_H$,$K_W$), 출력 크기를 (O_H,O_W)라 하면 출력 크기는 다음과 같이 계산한다.
-> $O_H$=$H$-$K_H$+1
-> $O_W$=$W$-$K_W$+1
가령, 28 X 28 dlqfurdmf 3 X 3 커널로 2차원 Conv 연산을 하면 26 X 26이 된다.
- 채널이 여러개인 2차원 입력의 경우 2차원 Convolution을 채널 개수만큼 적용한다고 생각한다

- 아래와 같이 계산 방법은 각 채널 별로 분리한 후 각 커널들에 2차원 Conv연산을 적용하면 된다.

채널의 개수가 같을 때, Conv연산의 결과값은 2차원의 값으로 나온다
($O_H$,$O_W$의 계산법은 윗 글과 동일)

만약에 채널의 개수가 다를 때는 아래와 같이 커널을 채널 개수만큼 쪼갠다. 그 결과는 커널을 $O_C$개가 나오는 텐서가 된다. 입력 벡터와 채널의 수와 커널 채널의 수가 동일해야하기 때문이다.

4.4 Convolution 연산의 역전파(Back progation)
- Convolution연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution연산이 나온다.



위 그림처럼 미분값 $\delta_1$, $\delta_2$, $\delta_3$가
각각 O1,O2,O3에 전달 되었다고 하고 어떻게 X3와 커널들에게 전달하는 지 봐야한다.
위의 위 그림에서 O1은 $w_3$, O2는 $w_2$, O3는 $w_1$가 각각 전달 되었다. 따라서, 역전파 단계에서 위 그림과 같이 그레디언트가 전달된다.

아까의 그림에서 O3는 $w_1$을 통해서 gradient 전달했기 때문에 커널 w1에는 $\delta _3$가 배당이 된다. 그 대신 $\delta _3$와 $x_3$을 곱해서 w1의 gradient가 된다. 나머지 w2,w3도 마찬가지이다. 다른 입력벡터에도 적용하여 일반화하면 아래와 같다.

'BoostCamp AI Tech - U Stage' 카테고리의 다른 글
| BoostCamp AI Tech - Day14 (0) | 2021.02.04 |
|---|---|
| BoostCamp AI Tech - Day13 (0) | 2021.02.04 |
| BoostCamp AI Tech - Day11 (0) | 2021.02.01 |
| BoostCamp AI Tech - Day10 (0) | 2021.02.01 |
| BoostCamp AI Tech - Day09 (0) | 2021.01.28 |



댓글