1. Generative Model
의미 : 생성모델
ex) GAN, VA
1.1 Learning a Generative Model(생성 모델을 학습하는 것)
- explicit model : 확률 값을 얻어 낼 수 있는 Generative Model
- implicit model : 단순히 Generating 하는 모델
- unsuperviesd representation learning : 공통적인 부분을 학습하는 것(ex. feature learning)
- p(x) : x가 입력했을 때, 어떤 값이 나올 수 가 있고, x를 샘플링할 수 있는 모델 일 수도 있다.
1.2 Basic Discrete Distributions
- Bernoulli distribution
(biased) coin flip. 즉, 결과가 0 또는 1이 나오는 것을 말한다.
만약에, 분포 D의 값이 Head,Tails가 있다고 하자. P(X=Heads) = p 라고 하면, P(X=Tails)=1-p이다.
표기는 $X$ ~ Ber($p$)
- Categorical distribution
(biased)m-sided dice, 주사위 처럼 다수의 카테고리가 나뉘어 있는 것
$D = {1,..,m}$ 일때, $P(Y=i) = p_i$,이므로 \sum_{i=1}^{m}p_i=1
표기는 $Y~Cat(p_1,...,p_m)$
예 1) Modeling an RGB joint distribution

총 경우의수는 256*256*256이다. 이에 대한 파라미터는 R,G,B는 독립적이고(indepentdant) Categorical distribution에서 256-1개씩 필요하므로, 255*255*255개씩 필요하다. 즉, 1개의 픽셀을 표현하기 위해서는 이정도의 파라미터가 필요한 것이다.
예 2) binary Images

위와 같은 binary 이미지가 n개씩 있다고 가정해보자. 총 경우의 수는 $2^n$ 개가 될 것이다. 또한, $p(x_1,...,x_n)$에서 이미지를 샘플링하고 이를 구분하는 파라미터의 개수는 $2^n-1$ 개가 될 것이다.
1.3 만약, $X_1, ... , X_n$ 들이 모두 독립(independent)적이라고 가정해보자(X는 coin flip)
그렇다면, 조건부 확률 식에의해, $p(x_1,...,x_n)=p(x_1)p(x_2)\cdots p(x_n)$이 성립한다. 따라서, 총 경우의 수는 $2^n$이 되고 $p(x_1,...,x_n)$ (distrubution)을 만들어가는 데 필요한 파라미터 수는 n개만 있으면 된다. 왜냐하면, 각 X는 모두 독립적이므로 1개씩 필요하므로 n개가 되는 것이다. 그러나, 파라미터가 확연히 줄어든 만큼, 원하는 이미지를 표현하기에 어려운 단점이 있다.
1.4 Conditional Independence
이러한 개념은 모두 독립적인 distribution과 Basic Discrete Distribution(Full dependent한 파라미터)의 중간적인 것을 만들려고 하는 생각에서 나온 것이다.
다음과 같이 세 가지의 중요한 정리가 있다.

※ Conditional independence : 임의의 변수 z가 주어졌을 때, 임의의 변수 x와 y가 독립적이면, $p(x|y,z)=p(x|z)$ 가 성립한다.
- Chain Rule에 필요한 파라미터수는 다음과 같다.

$ X_{i+1} \bot X_1, \cdots , X_{i-1} \bot X_i $ (Markov assumption) 이라고 가정하자( $\bot$ 은 두 변수가 독립이라는 의미) 그렇다면 아래의 식이 성립한다.

이에 필요한 파라미터 수는 $2n-1$ 개이다. 즉, Markov assumption을 가했더니, 파라미터수를 적절하게 바꾼것이다.
이를 활용하는 모델이 Auto-regressive Model 이라고 한다.
2. Auto-regressive Model

위와 같이 28 X 28 binary pixel이 있다고 가정하자. 목표는 이들의 확률 분포 $p(x)=p(x_1,\cdots , x_{784})$ 를 만들어가는 것이다. 그렇다면, p(x)를 파라미터화를 시킬 것인가? joint distribution을 형성하기 위해 체인 룰(chain rule)을 만들어 갈 것이다.( $ p(x_{1:784})=p(x_1)p(x_2|x_1)p(x_3|x_{1:2})\cdots $ ) 이것을 Auto-regressive Model 이라 부른다. Auto-regressive Model은 i번째 history가 $ 1, \cdots, i-1 $ 전체와 독립적인 경우도 포함된다. 또한, 임의의 변수에 대해서 순서를 매기는 것이 필요하다.
2.1 NADE(Nueral Autoregressive Density Estimator)

- NADE는 explicit Model로써, 임의의 입력이 주어지면 이에 대한 확률을 계산할 수 있다.
- 확률 계산 방법
아래와 같이 784 binary pixel이 있는 binary 이미지가 있다고 하자.
$ {x_1,x_2,\cdots ,x_{784}} $
그렇다면, joint probability는 다음과 같다. 단, 조건은 $p(x_i|p_{1:i-1})$의 값이 독립적으로 계산된다는 것이다.
p(x_{1:784})=p(x_1)p(x_2|x_1)\cdots p(x_{784}|x_{1:783})
연속적인 임의의 변수를 모델링할 때, 가우시안 혼합 모델(a mixture of Gaussian)이 사용되는 것이다.
2.2 Pixel RNN
n X n 크기의 RGB 픽셀로 이루어진 이미지가 있을 때,

위와 같이 i 번째 픽셀에 R을 만들고, G,B를 순차적으로 RNN의 형태로 만들어진다.
체인을 어떻게 ordering을 하느냐에 따라서, 아래와 같이 두 가지의 모델 아키텍처가 있다.
- Row LSTM
i 번째 pixel이 있을 때, 위쪽에 있는 정보를 활용하는 것이다

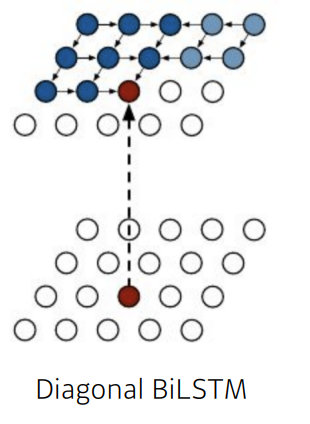
- Diagonal BiLSTM
양방향 LSTM을 활용하되, ordered된 pixel이 있을 때, 이전 정보의 RNN을 통하여 나타낸다.
'BoostCamp AI Tech - U Stage' 카테고리의 다른 글
| BoostCamp AI Tech - Day23 (0) | 2021.02.24 |
|---|---|
| BoostCamp AI Tech - Day16 (0) | 2021.02.15 |
| BoostCamp AI Tech - Day14 (0) | 2021.02.04 |
| BoostCamp AI Tech - Day13 (0) | 2021.02.04 |
| BoostCamp AI Tech - Day12 (0) | 2021.02.02 |




댓글